






芯片资讯
热点资讯
- 发布日期:2024-01-09 12:33 点击次数:182
语音识别技术,也被称为自动语音识别,目标是以电脑自动将以人类的语音内容转换为相应的文字和文字转换为语音。
一. 文本转换为语音
1.1 使用pyttsx
使用名为pyttsx的python包,可以将文本转换为语音。
安装pyttsx包
pip install pyttsx3
示例
import pyttsx3 as pyttsx
engine = pyttsx.init()
engine.say("Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。")
engine.runAndWait()
运行之后可以播放语音。
1.2 使用SAPI
在python 中,也可以使用SAPI 来将文本转换为语音。
使用Win32com.client包,不需要另外安装。
示例
from win32com.client import Dispatch
msg ="Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。"
speaker = Dispatch("SAPI.SpVoice")
speaker.Speak(msg)
del speaker
使用SpeechLib可以将文本转换为语音文件
使用SpeechLib,可以从文本文件中获取输入,再将其转换为语音文件。先使用pip安装,命令如下:
pip install comtypes
示例
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
infile = 'C:\Users\10619\Desktop\fileText.txt'
f = open(infile, 'r')
theText = f.read()
f.close()
outfile = 'demo_audio.wav'
engine = CreateObject("SAPI.SpVoice")
stream = CreateObject("SAPI.SpFileStream")
stream.Open(outfile,SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream = stream
engine.speak(theText)
stream.close()
运行之后,会输出demo_audio.wav语音文件,打开demo_audio.wav文件并播放。
二. 语音转换为文本
使用PocketSphinx包, PocketSphinx是一个用于语音转换文本的开源API。它是一个轻量级的语音识别引擎,尽管在桌面端也能很好的工作,SDIC(晶华微)半导体IC芯片 它还专门为手机和移动设备做过调优。首先使用pip命令安装所需模块,命令如下:
pip install PocketSphinx pip install SpeechRecognition
在安装PocketSphinx 可能会报错(ERROR: Could not build wheels for pocketsphinx, which is required to install pyproject.toml-based projects)。解决方法:通过查看pip可安装文件,查看可安装的文件命令:pip debug --verbose,然后查看Compatible tags: 33下可以安装的版本。
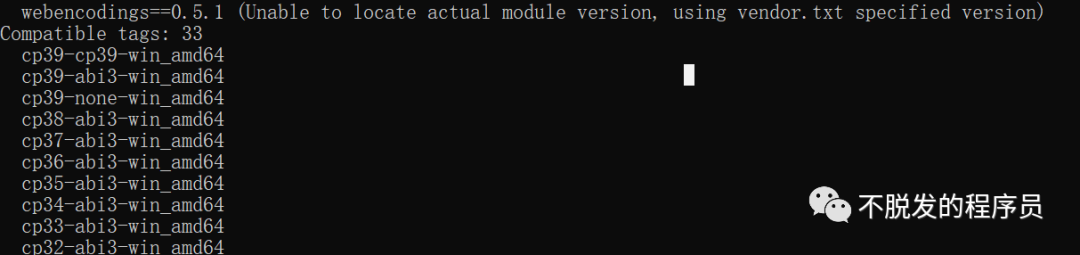
然后到https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx,下载对应版本的whl文件包安装。
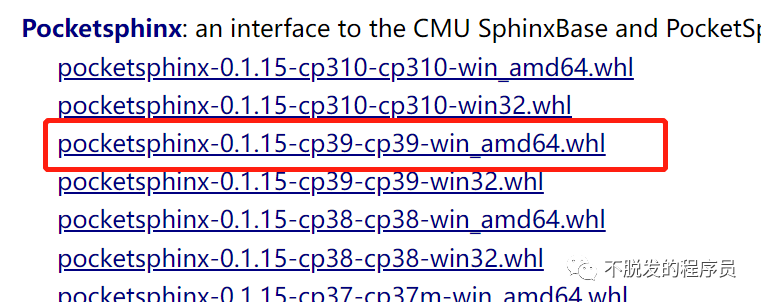

然后再安装PocketSphinx和SpeechRecognition包。

脚本示例
import speech_recognition as sr
r = sr.Recognizer()
audio_file = 'demo_audio.wav'
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
try:
print("文本内容:",r.recognize_sphinx(audio,language='zh-CN'))
#默认会识别为英文,如果要识别中文,需要下载普通话识别文件
except Exception as e:
print(e)
下载普通话识别文件。
下载路径:https://sourceforge.net/projects/cmusphinx/files/Acoustic and Language Models/Mandarin/
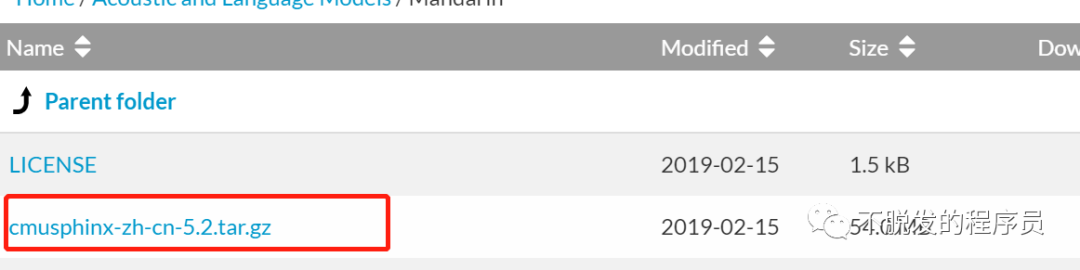
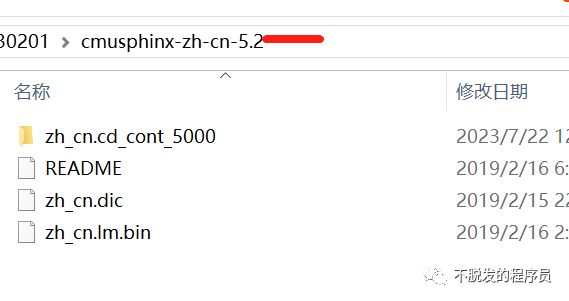
解压之后,修改文件名称,cmusphinx-zh-cn-5.2 改为 zh-CN, zh_cn.cd_cont_5000文件夹改为acoustic-model,zh_cn.dic改为pronounciation-dictionary.dict,zh_cn.lm.bin改为language-model.lm.bin。然后移动zn-CN文件夹到python3Libsite-packagesspeech_recognitionpocketsphinx-data下。
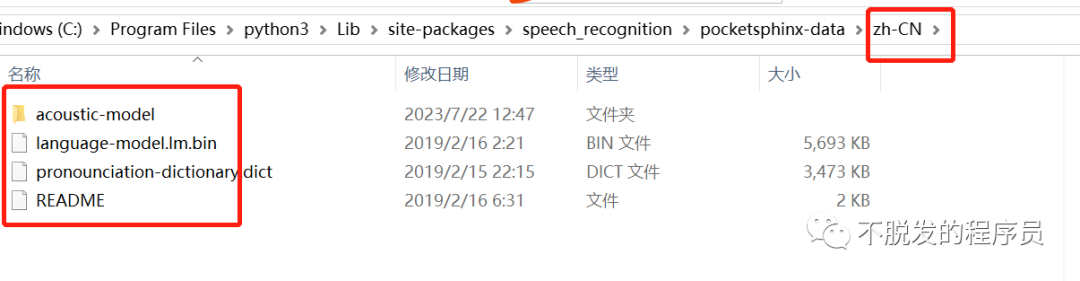
运行python之后,可以查看输出的文本内容。
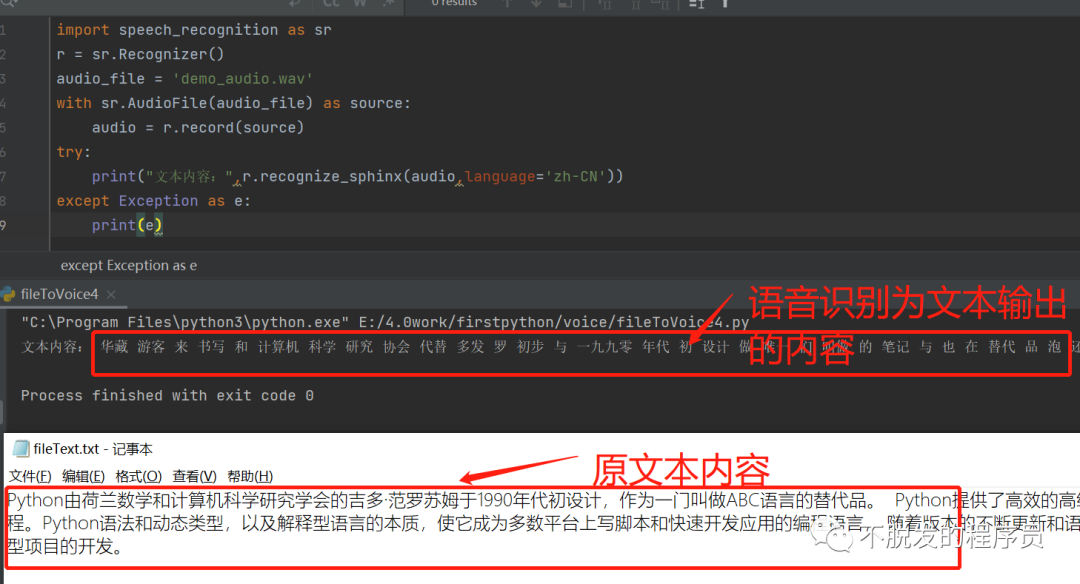
通过输出的语音转换之后的文本和原文本比较发现,语音识别的后文本还是有一定差异的。
编辑:黄飞
- 基于生物友好材料壳聚糖的摩擦纳米发电机的最新研究2024-01-05